(폐쇄망 LLM 7-5) Mistral-Vibe 설치
폐쇄망/내부망에서 Mistral-Vibe CLI 코딩 에이전트를 설치하는 방법. Python 가상환경으로 의존성을 격리하고 vLLM 서버와 연동하여 에이전틱 코딩 환경을 구축합니다.

이전 글: Open-WebUI 설치
이 글은 망분리 환경 AI 배포 시리즈의 열한 번째 글입니다.
다음 글: Qwen-Code 설치
이번 글의 목표
Open-WebUI로 웹 인터페이스를 구축했습니다. 이제 CLI 기반 에이전트 코딩 도구인 Mistral-Vibe를 설치해 봅시다.
중요: Mistral-Vibe는 서버가 아니라 각 사용자의 PC에 설치합니다. vLLM이나 Open-WebUI는 서버에 한 번 설치하면 여러 사용자가 접속해서 쓰지만, Mistral-Vibe는 코드를 읽고 수정하는 에이전트이기 때문에 개발자 각자의 업무용 PC에 설치해야 합니다.
Mistral-Vibe란?
Mistral-Vibe는 Mistral AI가 Devstral 모델과 함께 공개한 CLI 코딩 에이전트입니다. Claude Code와 비슷한 컨셉이지만 더 가볍고, Mistral 계열 모델들과 호환성이 좋습니다. Python 3.12 이상이 필요하고 pip로 간단히 설치할 수 있죠.
Part 1: 인터넷 환경에서 패키지 준비
1. Python 3.12 설치 확인
Mistral-Vibe는 Python 3.12 이상이 필요합니다. 먼저 설치된 버전을 확인하세요:
1
python --version
Python 3.12 미만이라면 Python 공식 사이트에서 3.12 이상 버전을 설치합니다.
2. 패키지 다운로드
pip download로 mistral-vibe와 모든 의존성을 다운로드합니다:
1
2
3
# 인터넷망에서
mkdir mistral-vibe
pip download mistral-vibe -d ./
.whl 파일들이 저장됩니다. 의존성이 꽤 많아서 대략 50-60개 정도 됩니다.
3. Python 설치 파일 준비
폐쇄망 PC에 Python 3.12가 없을 수 있으니 설치 파일도 함께 준비합니다. Python 공식 사이트에서 Windows용 설치 파일을 다운로드합니다:
python-3.12.x-amd64.exe(64비트 Windows용)
4. 설치 스크립트 준비
install.bat 파일을 만듭니다:
1
2
3
4
@echo off
cd /d "%~dp0"
pip install --no-index --find-links=. mistral_vibe-1.3.3-py3-none-any.whl
pause
5. 압축 및 전송
모든 파일을 한 폴더에 정리합니다:
1
2
3
4
5
6
mistral-vibe/
├── python-3.12.x-amd64.exe # Python 설치 파일
├── install.bat # 설치 스크립트
├── mistral_vibe-x.x.x-py3-none-any.whl
├── httpx-x.x.x-py3-none-any.whl
└── ... (기타 의존성 .whl 파일들)
폴더 전체를 압축해서 망간 자료 전송 시스템으로 폐쇄망에 옮깁니다.
Part 2: 업무망에서 설치
1. Python 설치
전송받은 mistral-vibe.zip의 압축을 풀고, python-3.12.x-amd64.exe를 더블클릭해서 Python을 설치합니다.
2. Mistral-Vibe 설치
install.bat을 더블클릭합니다. pip가 오프라인으로 패키지들을 설치합니다.
3. 설정 파일 생성
먼저 vibe를 한번 실행합니다. 처음 실행하면 .vibe 폴더가 자동으로 생성됩니다:
1
2
# 업무망에서
vibe
Ctrl+C로 종료한 뒤, %USERPROFILE%\.vibe 폴더에 config.toml 파일을 만듭니다. vLLM 서버와 연동하는 설정 예시입니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# %USERPROFILE%\.vibe\config.toml
active_model = "ministral-3b"
textual_theme = "gruvbox"
[[providers]]
name = "remote-server"
api_base = "http://{vLLM서버IP}:8080/v1"
api_key_env_var = ""
api_style = "openai"
backend = "generic"
[[models]]
name = "ministral-3b"
provider = "remote-server"
alias = "ministral-3b"
temperature = 0.2
active_model: vLLM에서 서빙 중인 모델 이름과 일치해야 합니다.curl http://{서버IP}:8080/v1/models로 확인할 수 있습니다.api_base: 실제 vLLM 서버 주소로 수정하세요.temperature: 응답의 다양성을 조절합니다. 0.2는 모델 권장값입니다 (모델마다 다릅니다).
4. 실행 확인
설정이 끝났으면 프로젝트 디렉토리에서 다시 vibe를 실행합니다:
1
2
# 업무망에서
vibe
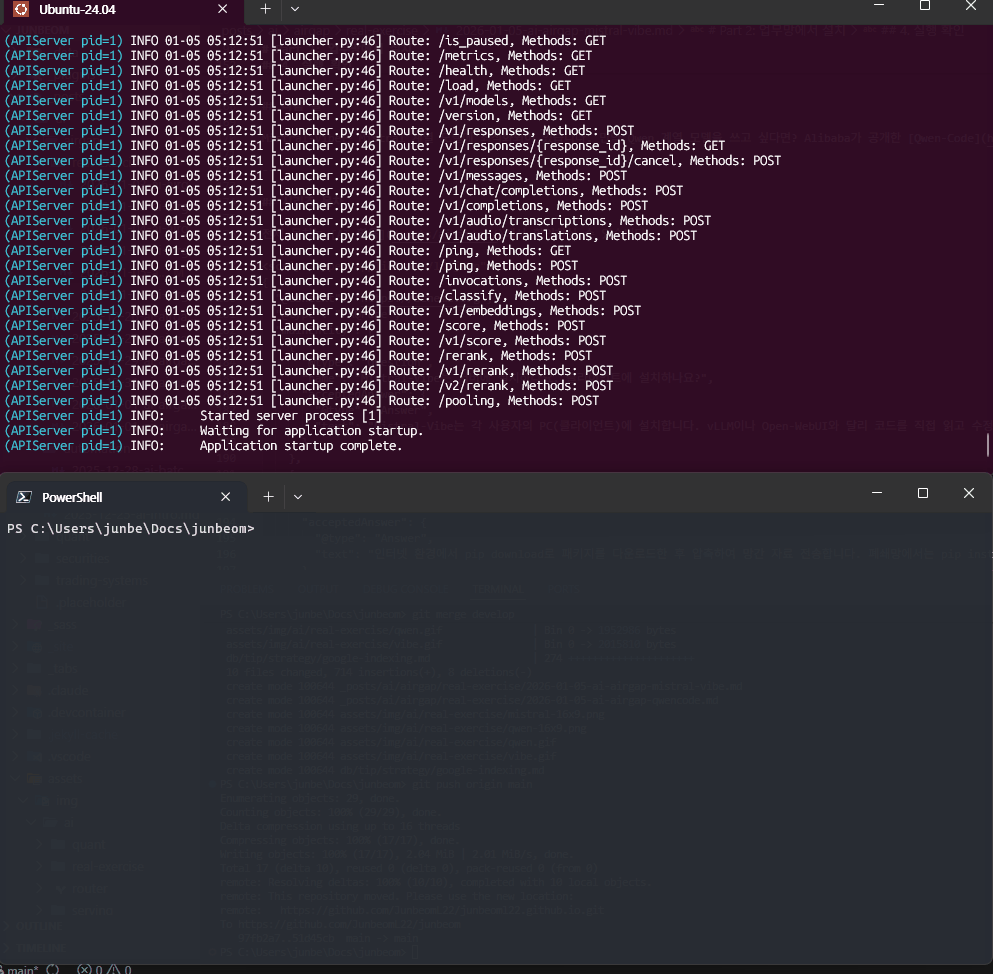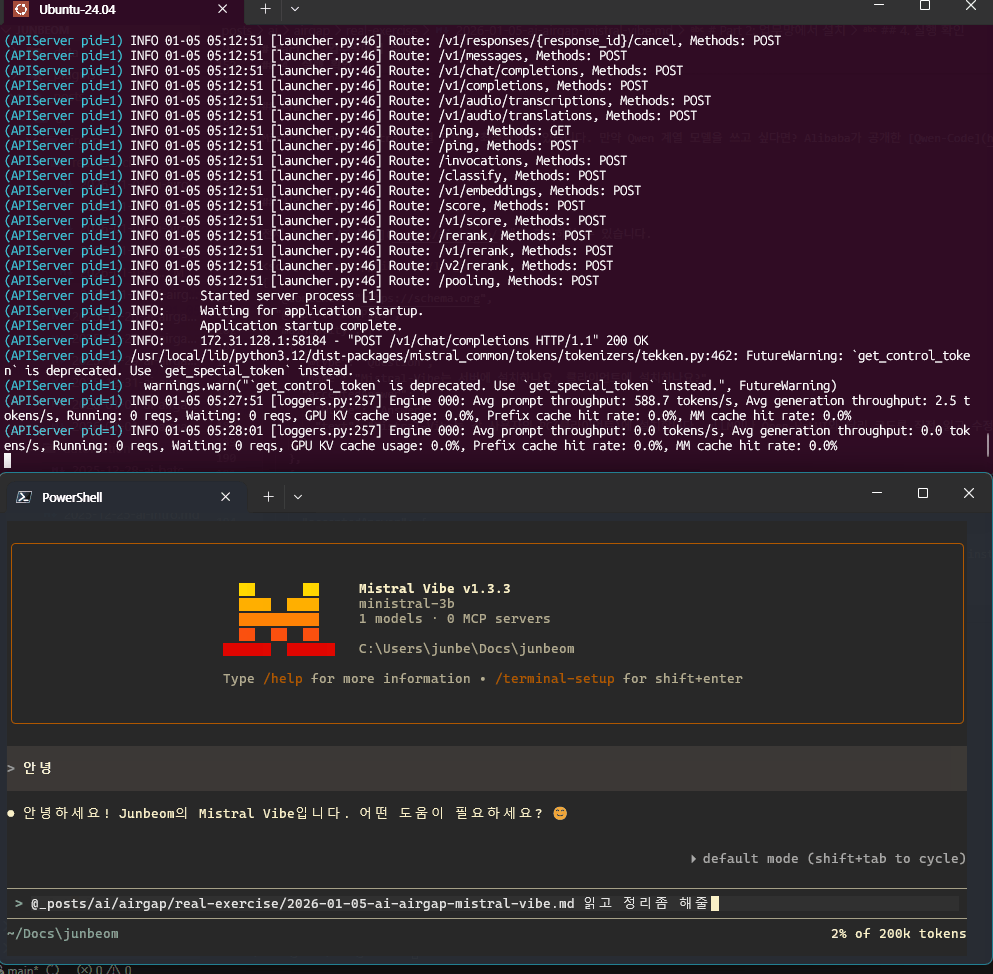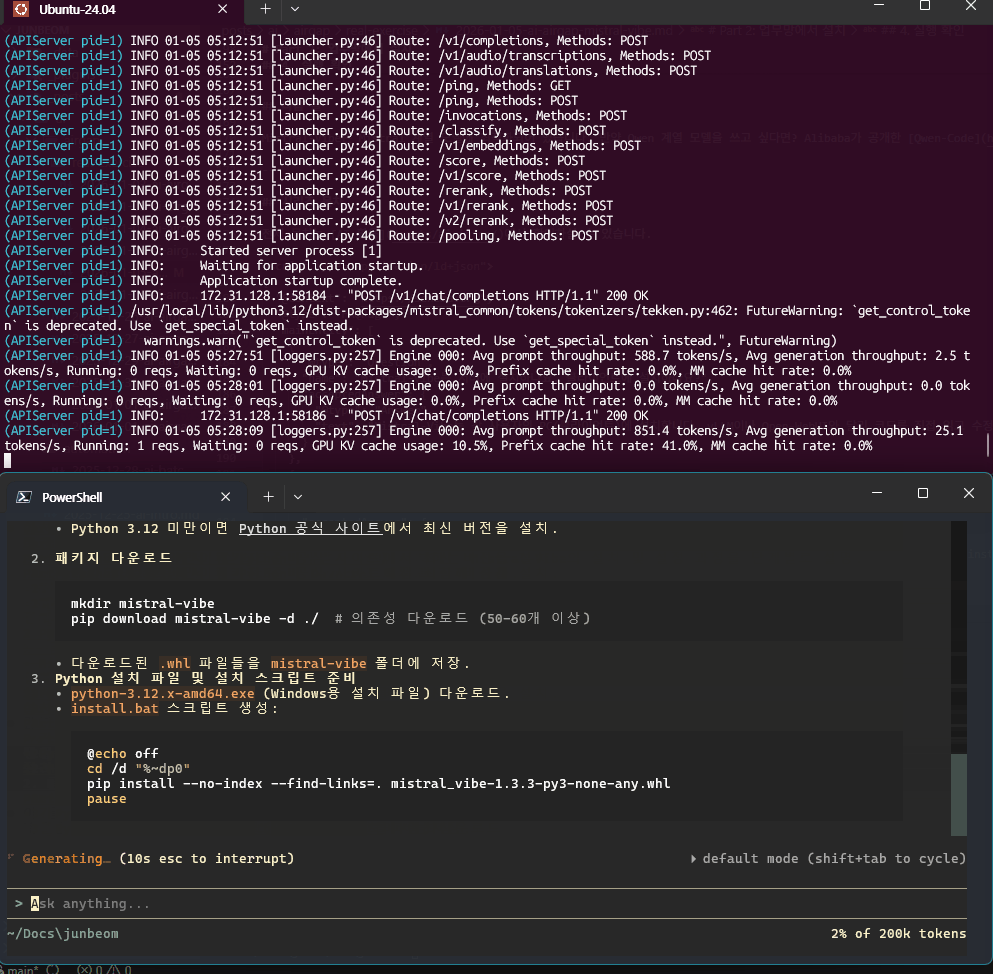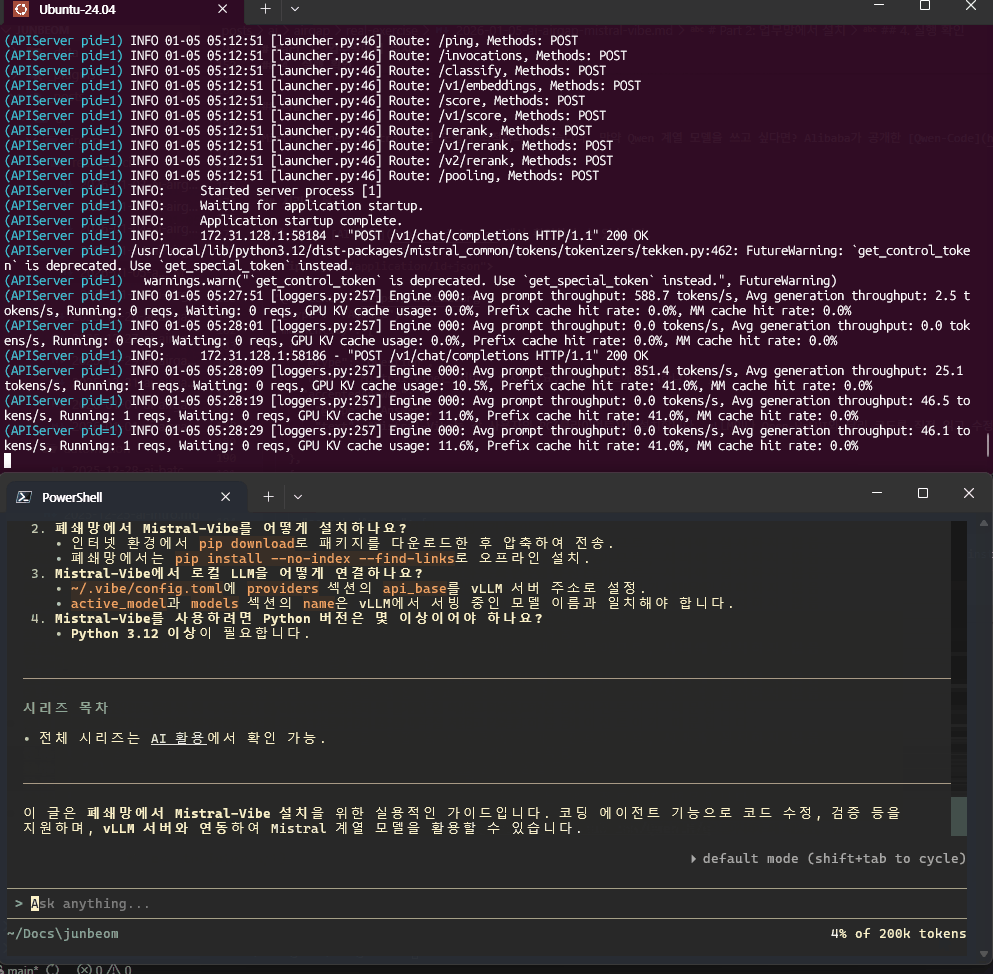 아래가 vibe, 위는 vLLM 로그로 prefill과 decode 속도를 보여 줍니다
아래가 vibe, 위는 vLLM 로그로 prefill과 decode 속도를 보여 줍니다
Mistral-Vibe가 실행되고 vLLM 서버와 연결되면 성공입니다. 지금 집에서 글을 작성하고 있는 관계로 (RTX 4060Ti) 작은 모델 Ministral-3-3B-Instruct 로 테스트 중입니다. 프로젝트 디렉토리에서 실행하면 코드베이스를 자동으로 인식하고, Claude Code처럼 파일을 읽고 수정하는 에이전틱 코딩이 가능해집니다.
다음 글
Mistral-Vibe는 Mistral 계열 모델에 최적화되어 있습니다. 만약 Qwen 계열 모델을 쓰고 싶다면? Alibaba가 공개한 Qwen-Code가 있습니다. 다음 글에서 Qwen-Code 설치 방법을 다룹니다.
시리즈 목차
전체 목차는 AI 활용에서 확인하실 수 있습니다.