(폐쇄망 LLM 3) 추론 속도와 MoE 모델 이해
폐쇄망/내부망 로컬 LLM 서버 구축 시 알아야 할 추론 속도(TPS) 개념. Prefill/Decode 차이와 MoE vs Dense 모델 비교를 통해 실무에서 모델 선택 기준을 제시합니다.
이전 글: 모델 선택과 메모리 요구량
이 글은 망분리 환경 AI 배포 시리즈의 세 번째 글입니다.
다음 글: 서빙 프레임워크 비교
추론 속도의 두 단계: Prefill (입력) 과 Decode (출력)
로컬 LLM의 속도를 이야기할 때 TPS (초당 토큰 수, token per second)가 자주 언급됩니다.
LLM의 문맥에서 속도는 입력과 출력 두 가지 단계에서 논의할 수 있습니다. 하지만 두 가지 단계의 성격과 하드웨어에서 영향을 주는 부분이 다르기 때문에 한번 꼼꼼히 살펴볼 필요가 있습니다.
적당한 모델을 선택했다면 어떤 하드웨어를 사용했을 때 쾌적하게 사용 가능한지 감은 있어야 하니까요.
결론을 먼저 얘기하고 시작하겠습니다:
- Prefill:
- 입력과정을 말함
- 굉장히 빠름. 일반적으로 속도를 얘기할 때 Prefill을 의미하지 않음
- 병렬 처리하므로 매우 빠름
- 가장 영향을 주는 GPU 스펙: 계산 Core
- Decode:
- 출력과정을 말함
- 일반적으로 속도를 말할 때는 Decode를 의미
- 토큰을 순차적으로 생성하므로 느림. 상용 모델이 100 t/s 정도
- 가장 영향을 주는 GPU 스펙: 메모리 대역폭
이제 위 내용을 하나씩 설명해 보겠습니다.
AI가 답변하는 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
┌───────────────────────────────────────────────────────────────┐
│ How LLM Generates a Response │
├───────────────────────────────────────────────────────────────┤
│ │
│ [User Question] │
│ "How do I make a delicious homemade pizza?" │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Step 1: Prefill │ │
│ │ - Process all input tokens in parallel on GPU │ │
│ │ - Calculate Attention between tokens at once │ │
│ │ - Generate KV Cache │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ [First token output: "To"] │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Step 2: Decode │ │
│ │ - Generate tokens one by one sequentially │ │
│ │ - Each token depends on previous tokens │ │
│ │ - "make a great pizza, start with..." token by token │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
└───────────────────────────────────────────────────────────────┘
Prefill
답변은 질문이 끝나야 할 수 있습니다. 다시 말해서 답변을 하고자 한다는건 질문이 완료가 됐다는 뜻이겠죠. LLM 은 질문의 처음과 끝을 이미 모두 알고 있으므로
모든 토큰을 동시에 처리합니다
GPU는 행렬 연산에 최적화되어 있어서, 토큰 1000개를 처리하나 100개를 처리하나 시간 차이가 크지 않습니다. 그래서 Prefill은 초당 수천~수만 토큰을 처리할 수 있습니다.
물론 계산 코어 수가 질문 토큰의 개수보다 적다면 데이터의 통신이 일어나면서 메모리 대역폭의 기능이 작용을 하겠지만 매우 미미한 영향만을 줍니다.
1
2
3
4
5
6
Input: "How do I make a delicious homemade pizza?"
↓
GPU calculates Attention for all tokens simultaneously (parallel)
↓
Done in a single (or short) forward pass
| 특성 | 설명 |
|---|---|
| 처리 방식 | 병렬 (Parallel) |
| 속도 | 1,000 ~ 30,000+ tokens/sec |
| 병목 | GPU 연산 능력 (Compute-bound) |
| 체감 | 0.0X초로 거의 인지 불가 |
Decode
Decode 단계는 완전히 반대 입니다. 내가 이전에 무슨 말을 했는지 알아야 다음 단어를 선택할 수 있습니다. 따라서 토큰을 하나씩 순차적으로 생성합니다.
1
2
3
4
Token 1: "To" -> done
Token 2: "make" -> done <- needs Token 1
Token 3: "a" -> done <- needs Token 2
Token 4: "great" -> done <- needs Token 3
다음 단어가 무엇인지는 이전 단어가 뭔지 알아야 결정할 수 있습니다. “나는 사과를…“이라고 했을 때, 다음에 “먹었다”가 올지 “샀다”가 올지는 문맥에 따라 달라집니다.
이 의존성 때문에 아무리 GPU가 빨라도 병렬화가 불가능합니다. 따라서 decode 단계에서는 커다란 청크 데이터를 한 번에 계산하는 것보다는 순차 계산이 여러 번 일어나면서 데이터 통신이 빈번하게 일어납니다. 따라서 decode에 가장 큰 영향을 주는 하드웨어 성능은 메모리 대역폭입니다.
| 특성 | 설명 |
|---|---|
| 처리 방식 | 순차 (Sequential) |
| 속도 | 50~100 tokens/sec 이면 빠르다고 느낌 |
| 병목 | 메모리 대역폭 (Memory-bound) |
| 체감 | 사용자가 기다리는 시간의 대부분 |
KV Cache의 역할
Decode가 바로 KV Cache에 의존합니다. KV Cache는 이전 글에서 설명한 것처럼 메모리를 더 써서 속도를 향상시킵니다. 정확히 말하면 KV Cache가 없으면 대화 자체가 거의 불가능하겠죠.
실전으로 감 잡아보기
한번 실전으로 어떤 GPU를 사면 속도가 얼마나 나올지 인터넷 검색을 하면서 제한된 정보로 감을 잡아보는 연습을 해보겠습니다.
실전 예시: 저는 RTX Pro 6000 Blackwell 96GB GPU를 사서 4명한테 서비스할 계획을 세우고 있습니다. 모델은 Devstral-Small-2-FP8 생각 중인데 속도(decode)가 얼마나 나올지 궁금합니다. 품질을 위해 KV Cache는 양자화하지 않고 BF16 혹은 FP16을 사용할 생각입니다. 인터넷을 검색하면 Reddit에 다음과 같은 사용 후기가 있습니다.
출처: https://www.reddit.com/r/LocalLLaMA/comments/1pm9xzg/vibe_devstral2_small/
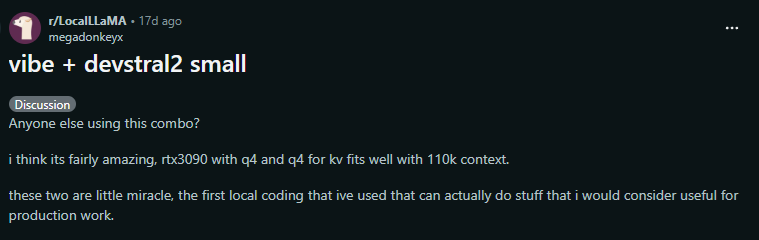
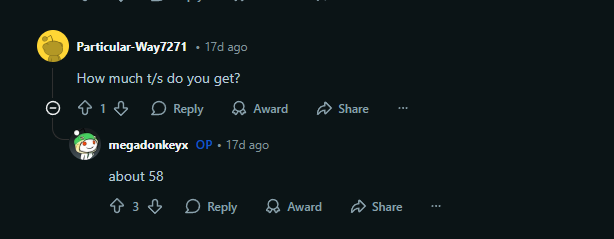
OP(original poster = 글쓴이)의 말에 따르면 RTX 3090으로 KV Cache를 Q4(4bit) 양자화했을 때 110k 컨텍스트에서 58t/s의 속도를 얻었다고 합니다. 잠깐 RTX 3090과 RTX PRO 6000의 스펙 차이를 보겠습니다:
| 항목 | RTX 3090 | RTX Pro 6000 Blackwell | 비율 |
|---|---|---|---|
| 아키텍처 | Ampere (GA102) | Blackwell | - |
| CUDA 코어 | 10,496 | 24,064 | 2.3x |
| 텐서 코어 | 328 (3세대) | 752 (5 세대) | - |
| 메모리 용량 | 24 GB GDDR6X | 96 GB GDDR7 + ECC | 4.0x |
| 메모리 인터페이스 | 384-bit | 512-bit | 1.3x |
| 메모리 대역폭 | 936 GB/s | 1,792 GB/s | 1.9x |
| 베이스 클럭 | 1,395 MHz | 1,590 MHz | 1.1x |
| 부스트 클럭 | 1,695 MHz | 2,617 MHz | 1.5x |
| 소비 전력 | 350W | 600W | 1.7x |
| PCIe 인터페이스 | PCIe 4.0 x16 | PCIe 5.0 x16 | - |
쿠다 코어, 텐서 코어, 부스트 클럭, 아키텍처 차이 등등 prefill은 당연히 압도적으로 더 높은 성능을 보여줄 것 같습니다. 그러나 decode 성능은 정말 여지없이 메모리 대역폭에서 대부분의 성능이 결정됩니다. 단순 계산입니다. RTX 3090으로 4bit에서 58t/s를 얻었습니다. 만약 16bit KV Cache를 사용 시 4배 더 많은 통신 비용이 발생합니다. 그런데 RTX Pro 6000은 메모리 대역폭이 RTX 3090에 비해 대략 2배 정도 됩니다. 110k 컨텍스트에서 대략 58t/s × 2 / 4 = 29t/s 정도가 될 것으로 예상됩니다. 실제로 RTX Pro 6000 장비에서 사용해 보면 시작 시 50t/s로 시작해서 128k 컨텍스트까지 20-30t/s로 떨어지는 걸 확인할 수 있습니다. 이 정도면 나쁘지 않은 속도입니다. 충분히 실사용 가능한 수준입니다
모델 크기의 딜레마와 해결책: MoE 아키텍처
지금까지 속도에 대해 알아봤는데요, 모델 사이즈가 커지면 성능은 좋아지지만 모델 메모리와 KV Cache 메모리가 커지고 속도는 느려집니다. 이런 딜레마를 극복할 수 있는 방법이 없을까요?
앞서 잠깐 GLM-4.7 모델은 MoE(Mixture of Experts) 모델이라서 단순히 파라미터 비율만큼 메모리가 커지지는 않는다고 말씀드렸는데요, 조금 더 자세히 설명드리겠습니다.
Dense (전통적) 모델
전통적인 모델을 우리는 Dense 모델이라고 부릅니다.
1
2
3
4
5
6
7
┌─────────────────────────────────────────────────────────────┐
│ Dense Model (Transformer) │
├─────────────────────────────────────────────────────────────┤
│ Input Token -> [Attention Layer] -> [FFN Layer] -> Output │
│ ↑ │
│ All parameters used │
└─────────────────────────────────────────────────────────────┘
특징: 질문이 수학이든 역사든, 모든 파라미터가 계산에 참여
예시: Qwen 2.5 Coder-Instruct, Devstral, Llama 시리즈
Dense 모델의 구조적 한계는 분명합니다. 성능을 높이려면 파라미터를 늘려야 하는데, 이는 계산량과 메모리 사용량이 선형적으로 증가함을 의미합니다.
1
파라미터 2배 → 계산량 2배 → 메모리 2배 → 속도 1/2
MoE (Mixture of Experts) 모델
MoE는 이 문제를 “필요한 전문가만 호출하자”는 아이디어로 해결합니다.
1
2
3
4
5
6
7
8
9
10
11
12
┌──────────────────────────────────────────────────────────────┐
│ MoE Model │
├──────────────────────────────────────────────────────────────┤
│ Input -> [Attention] -> [Router] -> [Expert Selection] │
│ │ │
│ ┌────────────┼────────────┐ │
│ ↓ ↓ ↓ │
│ [Expert 1] [Expert 2] ... [Expert N] │
│ │ │
│ ↓ │
│ Only selected experts computed -> Output │
└──────────────────────────────────────────────────────────────┘
핵심 원리:
- Attention Layer는 그대로 유지
- FFN Layer만 여러 “전문가(Expert)”로 분할
- Router가 각 토큰마다 “이건 수학 질문이니 Expert 3을 쓰자”라고 결정
MoE의 효율성: 전체 vs 활성 파라미터
| 모델 | 총 파라미터 | 활성 파라미터 | 활성화 비율 |
|---|---|---|---|
| GLM-4.5-Air | 106B | 12B | 11% |
| Qwen3-30B-A3B | 30B | 3B | 10% |
| DeepSeek-V3 | 671B | 37B | 약 5.5% |
의미: 671B짜리 DeepSeek-V3는 실제로는 37B짜리 Dense 모델 수준의 계산량만 사용
KV Cache 관점에서의 MoE
여기서 중요한 점이 있습니다. KV Cache는 Attention Layer에서만 생성됩니다.
1
2
3
4
5
KV Cache = Attention Layer에서 생성 (Key, Value 저장)
MoE = FFN Layer만 대체
→ MoE는 FFN만 확장하고, Attention은 그대로
→ 같은 hidden_size면 KV Cache는 동일
MoE의 강점: “지식”은 늘리면서(Via Expert 수 증가) KV Cache는 덜 늘릴 수 있습니다.
2025년 트렌드: MoE가 대세
요즘 한 번쯤 이름을 들어본 모델들은 대부분 MoE 아키텍처입니다.
| 모델 | 아키텍처 | 총 파라미터 | 활성 파라미터 | Expert 수 |
|---|---|---|---|---|
| DeepSeek-V3 | MoE | 671B | 37B | 256 |
| GLM-4.5-Air | MoE | 106B | 12B | 128 |
| MiniMax-M2 | MoE | 229B | 10B | - |
| Qwen3-Coder | MoE | 480B | 35B | 160 |
| Kimi K2 | MoE | 1T | 35B | 384 |
MoE가 대세인 이유
- 계산 효율성:
- 전체 파라미터 대비 적은 계산량으로 비슷한 성능 달성
- 실제로 24B 모델인 devstral-small-2-24b 모델보다 107B 파라미터인 GLM-4.5-Air 모델이 더 빠릅니다
- 메모리 효율성: 동일 성능 기준 KV Cache가 더 적음
전체 파라미터 대비 훨씬 적은 계산량을 사용하므로 실제로는 매우 효율적입니다.
그래서 제가 쓰는 모델은..
2025년 12월 현재는 Dense 모델을 씁니다. 2025년 12월에 특이하게 굉장히 좋은 Dense 모델 Devstral-2가 나왔거든요.
좋은 건 좋은 거고 대세는 대세지만, 항상 정답은 없습니다. 각자의 상황, 예산, 요구사항 등에 맞춰서 모델을 선택하시면 됩니다.
실제 사용 경험
Devstral-Small-2-24B를 Mistral-Vibe와 연동해서 사용해봤습니다. Mistral-Vibe는 망분리 환경에서 CLI 기반 AI 코딩 도구로 활용하기에 매우 적합한 도구입니다. (설치 가이드)
장점:
- 코딩 성능이 상당히 준수
- Dense 모델이라 양자화에 강건
- 24B로 VRAM 요구량이 적당
단점:
- mistral-vibe와 연동 시 사소한 버그들이 있음
현재 사내 사용 조합
1
2
모델: Devstral-Small-2-24B-Instruct-FP8
클라이언트: mistral-vibe 로 agentic coding & open-webui 로 간단한 채팅
FP8 양자화로 VRAM을 절약하면서도 성능 저하가 적습니다. Dense 모델이라 양자화 안정성도 좋습니다.
모델이 클수록 양자화에 강한데, MoE 모델의 경우 실제 계산에 참여하는 파라미터는 적어서 그런지 체감상 양자화에 민감하다는 느낌이 있습니다.
모델 링크: Hugging Face - Devstral-Small-2-24B-Instruct-2512
정리!
LLM 추론 속도에는 Prefill(입력)과 Decode(출력) 두 단계가 있습니다:
- Prefill:
- 입력 토큰을 병렬 처리하므로 매우 빠름
- 하드웨어에서 중요한 부분은 코어와 클럭등 compute bound 한 부분
- Decode:
- 토큰을 순차적으로 생성하므로 느림 50 tps 이상이면 준수한 수준
- 일반적으로 속도라면 Decode를 의미
- 하드웨어에서 중요한 부분은 메모리 대역폭
- Prefill:
현시점 대세는 MoE
- 메모리와 속도 모두 효율적
- Deepseek, GLM, MiniMax 등 모두 MoE 아키텍처
- Devstral 같이 준수한 Dense 모델도 충분히 경쟁력이 있음
다음 글
모델을 선택했으면 이제 실제로 서비스로 운영할 차례입니다. 다음 글에서는 vLLM, SGLang, llama.cpp, Ollama등 주요 서빙 프레임워크의 특징과 장단점을 비교해 보겠습니다.
시리즈 목차
전체 목차는 AI 활용에서 확인하실 수 있습니다.