(폐쇄망 LLM 5) 양자화와 정밀도 선택 가이드
폐쇄망/내부망에서 로컬 LLM 서버 구축 시 양자화 기법 선택 가이드. FP8, AWQ, GPTQ, GGUF의 특징과 vLLM, llama.cpp 호환성을 정리합니다.

이전 글: 서빙 프레임워크 비교
이 글은 망분리 환경 AI 배포 시리즈의 다섯 번째 글입니다.
다음 글: Claude Code Router 설정
양자화가 뭔가요?
서빙 프레임워크를 선택했습니다.
돌리고 싶은 모델이 있는데, 음…메모리가 부족합니다. 이럴 때 양자화가 대안입니다. 실질적으로 대안이 아니라 필수입니다 ^^; 양자화(Quantization)는 모델의 가중치를 고정밀도에서 저정밀도로 변환하여 메모리 사용량을 줄이는 기법입니다. 쉽게 말해:
1
2
FP32 (32비트) → FP16/BF16 (16비트) → FP8/INT8 (8비트) → INT4 (4비트)
4GB 2GB 1GB 0.5GB
절반 비트로 표현하면 메모리도 절반이 됩니다. 대신 성능은 살짝 떨어지겠죠 (절반으로 떨어지지는 않습니다!) 이 트레이드오프를 잘 타협하는 것이 양자화의 핵심입니다.
Note: 양자화는 모델과 KV Cache 모두 적용 가능합니다
실제로 AI 로컬 서비스에서는 FP32 모델을 거의 사용하지 않습니다. HuggingFace에 올라오는 원본 기본 모델이 16비트부터 올라와서 저희가 예전부터 프로그래밍 문맥에서 쓰이는 일반적인 32/64비트 실수 타입과는 다릅니다. 일반적으로 16비트는 그냥 양자화를 하지 않았다고 느껴지긴 합니다.
일단 16비트부터 설명해 보겠습니다. 16비트 표현법에는 두 가지 방식이 있습니다.
FP16 vs BF16
FP16 (Half Precision)
FP16은 IEEE 754 표준의 반정밀도 부동소수점입니다. 1비트 부호, 5비트 지수, 10비트 가수로 구성됩니다.
1
2
3
4
5
FP16: [S][EEEEE][MMMMMMMMMM]
1bit 5bits 10bits
표현 범위: ±65504
정밀도: 약 3~4자리 십진수
장점:
- 10비트 가수로 높은 정밀도
- Volta(V100) 아키텍처부터 지원
- 추론에 적합
단점:
- 5비트 지수로 동적 범위가 좁음
- 큰 값에서 오버플로우 가능
BF16 (Brain Float)
BF16은 Google Brain이 개발한 16비트 포맷입니다. FP32와 동일한 8비트 지수를 유지하는 게 핵심입니다.
1
2
3
4
5
BF16: [S][EEEEEEEE][MMMMMMM]
1bit 8bits 7bits
표현 범위: ±3.38×10^38 (FP32와 동일)
정밀도: 약 2자리 십진수
장점:
- FP32와 동일한 지수 범위로 오버플로우 방지
- 대규모 모델 학습에 최적화
- Ampere(A100) 이상에서 하드웨어 가속
단점:
- 7비트 가수로 FP16 대비 정밀도 저하
- Ampere 이상에서만 네이티브 지원
FP16 vs BF16 선택
| 용도 | 추천 | 이유 |
|---|---|---|
| 추론 | FP16 | 더 높은 정밀도 |
| 대규모 학습 | BF16 | 학습 안정성 |
| vLLM 서빙 | FP16/BF16 | 둘 다 지원 |
보통 모델은 8비트 정도 쓰면 충분히 성능 저하 없이 사용 가능하긴 합니다 (그래도 종종 체감은 됩니다). 그래서 일반적으로 모델을 16비트를 쓰는 경우는 잘 없습니다. KV Cache 타입은 얘기가 좀 다른데요, 이것도 당연히 모델에 따라 편차가 심한데 16비트 이하의 양자화로 가면 확연히 성능에 영향을 주는게 체감 됩니다. 모델 양자화랑 별개의 방식으로 성능에 영향을 주는데 KV Cache 양자화 시 컨텍스트가 길어지면 길어 질수록 성능이 팍팍 떨어 집니다.
자 이제 본격적으로 양자화의 영역인 8비트입니다.
FP8: 8비트 부동소수점의 등장
FP8은 8비트 부동소수점으로, NVIDIA H100(Hopper) 및 RTX 40-series(Ada Lovelace) 아키텍처에서 네이티브 지원합니다.
두 가지 FP8 포맷
| 포맷 | 구조 | 표현 범위 | 특징 |
|---|---|---|---|
| E4M3 | 1비트 부호 + 4비트 지수 + 3비트 가수 | [-448, 448] | 높은 정밀도 |
| E5M2 | 1비트 부호 + 5비트 지수 + 2비트 가수 | [-57344, 57344] | 넓은 범위 |
1
2
E4M3: [S][EEEE][MMM] E5M2: [S][EEEEE][MM]
1bit 4bits 3bits 1bit 5bits 2bits
왜 FP8인가?
Int8 등 FP8 과 달리 정수형 양자화 방식도 존재 합니다. 그러나 FP8은 부동소수점 표현을 유지하므로 Outlier 처리에 우수합니다. 대규모 트랜스포머 모델에서는 가끔씩 매우 큰 값(Outlier)이 나오는데, 이를 처리할 수 있는 동적 범위가 중요합니다.
따라서, FP8의 최대 장점은 원본에 가까운 품질을 보존한다는데 있습니다.
더불어 다음 장비들에서 하드웨어 수준에서 가속 지원 합니다:
| SM 계열 | 아키텍처 | 주요 GPU |
|---|---|---|
| SM120 | Blackwell | RTX 50xx, RTX Pro 6000 Blackwell |
| SM100 | Blackwell | B100/B200, GB200 |
| SM90 | Hopper | H100, H200 |
| SM89 | Ada Lovelace | RTX 40xx, RTX 6000 Ada, L40S, L40, L4 |
FP8 포맷 파일은 다음 프레임워크에서 구동가능합니다
서빙 프레임워크 지원
| 프레임워크 | FP8 지원 |
|---|---|
| vLLM | ✅ |
| SGLang | ✅ |
| llama.cpp | ❌ |
자 이제부터 4bit의 영역인데요. 이제부터 진짜 양자화를 해봤다 싶은 수준입니다. AWQ와 GPTQ 형식에 대해서만 간단하게 짚어 보도록 하겠습니다. 두 형식 모두 8bit로도 가능한데 특별한 이유(임시적 호환성 등)가 없으면 8bit를 사용하지는 않습니다.
GPTQ & AWQ
Calibration 데이터?
두 양자화 기법 모두 calibration 데이터를 사용합니다. 양자화할 때 “이 모델이 실제로 어떻게 동작하는지” 관찰하기 위한 샘플입니다. 옷을 줄일 때 입어보면서 “여기는 꽉 끼네”, “여기는 여유있네” 확인하는 것과 비슷합니다. 보통 128~1000개 정도의 일반 텍스트를 모델에 통과시켜서 “이 레이어는 activation이 크네”, “이 weight는 중요하네”를 측정합니다. 학습용이 아니라 통계 수집용입니다.
- GPTQ
- Hessian 기반으로 layer-wise reconstruction/optimization을 수행
- Backpropagation은 아니지만 무거운 최적화 계산이 있음
- Calibration 데이터에 overfitting 경향이 있음
- 그래서 양자화 과정이 느림
- AWQ
- Activation 통계를 단순히 측정만 함
- Backpropagation이나 reconstruction 과정이 전혀 없음
- Scale factor만 계산하면 끝
- Calibration 데이터가 적게 필요하고 overfitting 위험 낮음
- 그래서 양자화 과정이 빠름
서빙 프레임워크 지원
| 프레임워크 | GPTQ | AWQ |
|---|---|---|
| vLLM | ✅ GPTQModel 통합 | ✅ Ampere GPU+ |
| SGLang | ⚠️ GPU 지원 / NPU 미지원 | ✅ 완전 지원 |
| llama.cpp | ⚠️ GGUF로 변환 필요 | ⚠️ GGUF로 변환 필요 |
이런 저런 이유로 GPTQ 보다는 AWQ 를 더 선호 하는 추세 입니다.
GGUF: llama.cpp 전용 모델 형식
GGUF는 llama.cpp 프로젝트에서 개발된 바이너리 파일 형식입니다. 엄밀히 말해 양자화 알고리즘이라기보다는 모델을 저장하고 실행하는 컨테이너 형식에 가깝습니다.
K-quants 포맷
GGUF는 자체적인 K-quants 양자화 방식을 지원합니다:
1
2
3
4
5
Q4_K_M: 약 4.9 bits per weight (가장 인기있는 밸런스)
Q5_K_M: 약 5.5 bits per weight (더 높은 정확도)
Q3_K_M: 약 3.5 bits per weight (더 낮은 메모리)
K-quants는 중요한 레이어에 더 많은 비트를 할당하는 방식입니다.
한번 연습 삼아 현재 트렌드 파악도 해보고 양자화 모델 다운 받아 보는 것도 해보겠습니다. 아 참고로 양자화는 저희가 직접 하지 않습니다. 서비스하는 것만으로도 벅찹니다. 양자화를 열심히 해서 올려주시는 분들이 계시니 기다렸다 쓰면 됩니다. 자 한번 쓱 둘러 볼까요?
트렌드 확인 및 양자화 다운로드
먼저 HuggingFace/models에 방문해 보겠습니다. 그러면 기본적으로 treding으로 정렬된 모델리스트가 보입니다:
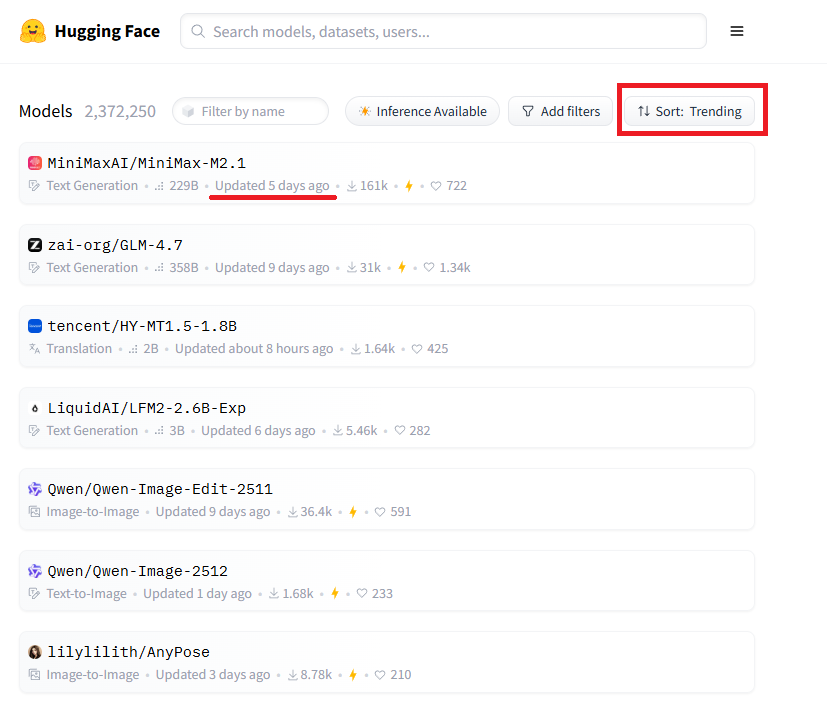 Trending List
Trending List
여기서 2026년1월1일 기준 최상단에 위치한 MiniMax-M2.1 을 클릭해 보겠습니다:
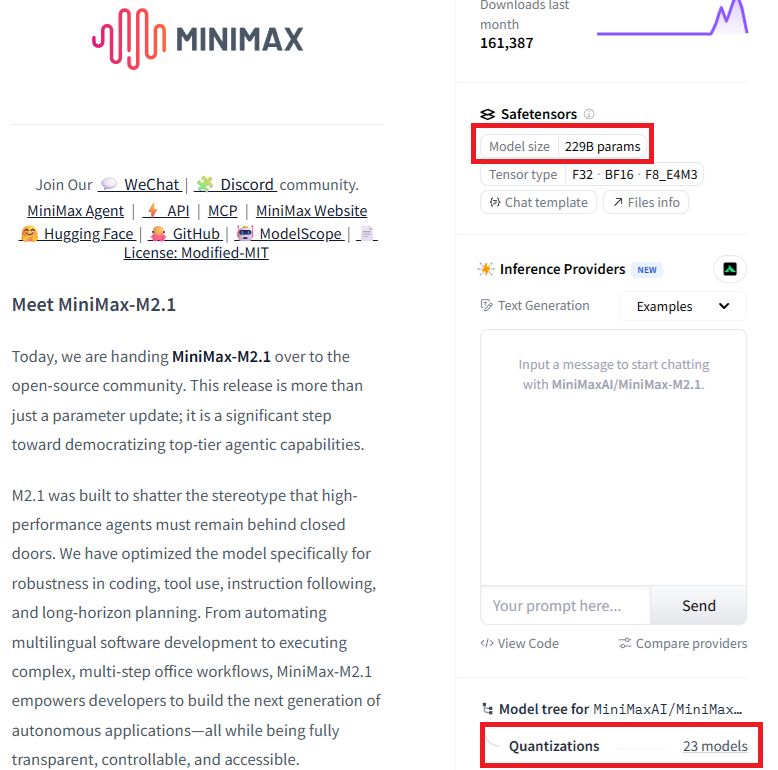 MiniMax-M2.1
MiniMax-M2.1
몇가지 정보가 보입니다. 설명을 보면, 뭐 엄청난 발전이 있었고, 코딩과 툴콜에 최적화를 했고..그리고.. 파라미터는 229B개나 되네요? 이거 FP8로 혼자 써도 필요한 VRAM이 260GB는 거뜬하게 넘을 것 같네요. 양자화 모델이 있나 한번 찾아 볼까요? 하단에 Quantization 을 보면 23 models 라고 되어 있습니다. 한번 클릭해 보겠습니다.
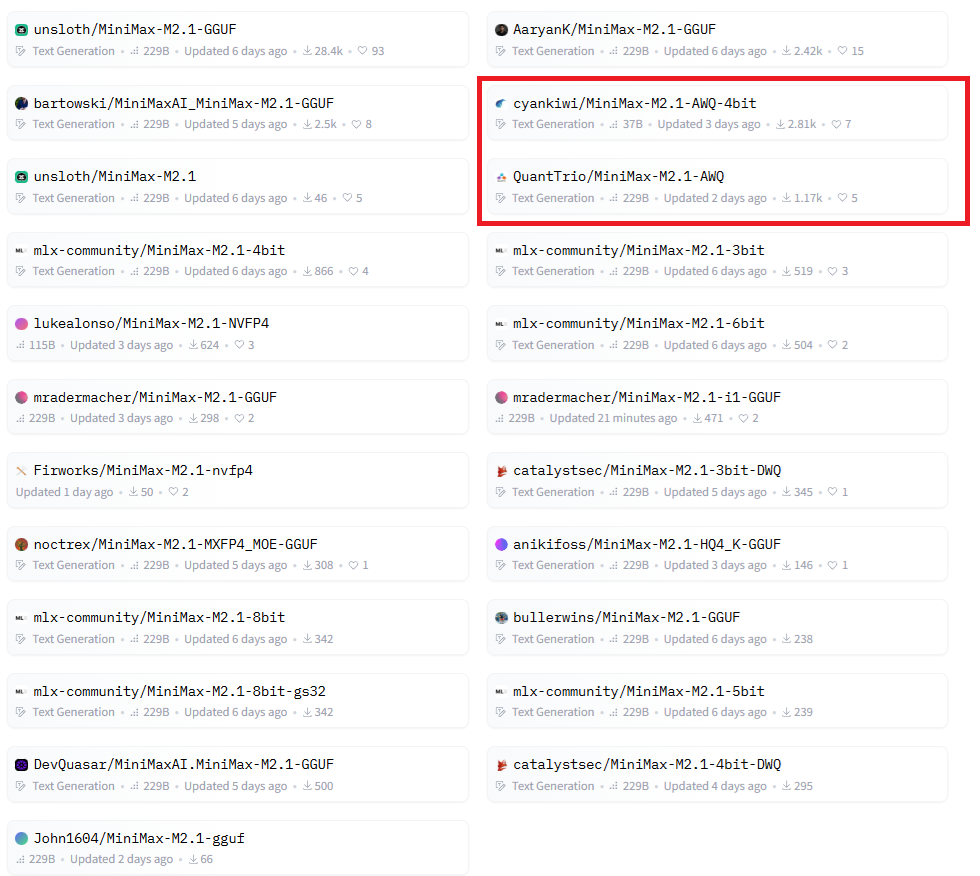 MiniMax-M2.1 quantization list
MiniMax-M2.1 quantization list
AWQ 모델이 두 개 보이고 GPTQ 모델은 보이지 않습니다. GGUF 모델이 상당히 많네요. 개인용도로 사용하는 사람이 로컬 모델 수요의 대다수라고 해석됩니다. 제가 설명 안 한 모델도 많이 보입니다. NVFP4, MLX, DWQ 등등. 양자화도 설명을 하자면 끝이 없는데 하나만 간단히 추가 설명하면 MLX는 Mac 전용 모델입니다.
AWQ 중에 최상단에 있는 cyankiwi 모델을 다운 받아 보겠습니다.
먼저 huggingface-cli를 설치합니다.
1
pip install huggingface-cli
그 다음 내가 모델을 저장하고 싶은 위치로 가서 모델을 다운로드합니다:
1
hf download cyankiwi/MiniMax-M2.1-AWQ-4bit --local-dir ./MiniMax-M2.1-AWQ-4bit
다운로드가 시작되면 진행 상황이 표시됩니다:
1
2
Downloading (incomplete total...): 0%| | 764k/40.0G [00:02<40:09:41, 277kB/s]
Fetching 52 files: 0%| | 0/52 [00:00<?, ?it/s
이렇게 보이면 다운로드가 시작된 것입니다. 처음에는 40GB로 표시되지만, 다운로드가 진행되면서 실제 크기가 나타납니다. 최종적으로 229B 파라미터의 4bit 양자화 모델이므로 약 120GB를 다운로드하게 됩니다.
다운로드가 완료되면 ./MiniMax-M2.1-AWQ-4bit 디렉토리에 모델 파일들이 저장됩니다. 인터넷이 되는 환경에서 이런 식으로 모델을 다운받아서 업무망으로 옮긴 후 vLLM으로 이 모델을 실행시키면 됩니다. 이후 섹션에서 자세히 다루도록 하겠습니다.
요약
- FP8은 원본에 유사한 품질 & 몇몇 장비는 하드웨어 가속 지원
- FP8을 사용하기 어렵고 다중 사용자 서비스가 필요하다면 AWQ 추천
- KV Cache는 16비트 추천 (특히 긴 컨텍스트 작업이 필요하다면)
- GPU 자원이 부족하거나 개인용도라면 GGUF
- GPTQ는 잘 사용하지 않는 추세
제가 사용하는 조합
1
2
3
모델: Devstral-Small-2-24B-FP8
프레임워크: vLLM
KV Cache: BF16 (양자화하지 않음)
FP8 모델을 사용하면서도 KV Cache는 양자화하지 않는 이유는 모델 선택 글에서 설명했듯이 컨텍스트가 길어질수록 품질 손실이 체감되기 때문입니다.
다음 글
양자화와 서빙 프레임워크를 선택했다면 이제 실제로 배포하고 운영할 차례입니다. 다음 글에서는 openrouter에서 API를 받아서 Claude-Code-Router를 이용해 Claude-Code와 연동하는 연습을 해보겠습니다. 여기서 openrouter API만 vLLM으로 바뀌면 저희의 궁극적 목표인 망분리 환경에서 agentic coding을 구현할 수 있게 되는 겁니다.
시리즈 목차
전체 목차는 AI 활용에서 확인하실 수 있습니다.