(폐쇄망 LLM 7-6) Qwen-Code 설치
사내 AI 코딩 에이전트 구축 - 업무망/폐쇄망에서 Qwen-Code CLI를 설치하고 vLLM 서버와 연동하여 에이전틱 코딩 환경을 구축합니다.

이전 글: Mistral-Vibe 설치
이 글은 망분리 환경 AI 배포 시리즈의 마지막 글입니다.
2026-05-02 수정: 한 달 넘게 사내에서 실제 배포·운영 중인 모델이 Qwen 계열이라, 그동안 정착된 설정을 반영해 vLLM
docker-compose.yml과 Qwen-Code의settings.json부분을 현행 기준으로 다시 정리했습니다.
이번 글의 목표
이전 글에서 Mistral-Vibe를 설치했습니다. 이번에는 Alibaba가 공개한 Qwen-Code를 설치해봅시다. 글을 쓰는 시점의 Qwen-Code 버전은 v0.15.6입니다.
Qwen-Code도 클라이언트 도구입니다. Mistral-Vibe와 마찬가지로 각 사용자의 PC(클라이언트)에 설치합니다.
Qwen-Code란?
Qwen-Code는 Alibaba가 Qwen 모델과 함께 공개한 CLI 코딩 에이전트입니다. Claude Code나 Mistral-Vibe와 비슷한 컨셉이고, Node.js 기반이라 npm으로 설치합니다. Qwen 계열 모델들과 호환성이 좋고, tool calling을 지원합니다.
1. vLLM 서버 설정
Qwen 모델로 tool calling을 사용하려면 vLLM 실행 시 Qwen 전용 파서 옵션을 붙여줘야 합니다. 개인 컴퓨터(RTX 4060Ti)라서 작은 모델 Qwen3.5-9B-AWQ-4bit로 테스트했습니다. docker-compose.yml의 핵심 부분만 보면 다음과 같습니다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
services:
vllm:
image: vllm/vllm-openai:latest
container_name: vllm-qwen3
runtime: nvidia
ports:
- "8080:8080"
volumes:
- /home/junbeom/local-models/Qwen3.5-9B-AWQ-4bit:/models/qwen3.5-9b:ro
command: >
--model /models/qwen3.5-9b
--served-model-name qwen3p5
--quantization compressed-tensors
--max-model-len 32768
--gpu-memory-utilization 0.90
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--trust-remote-code
--host 0.0.0.0
--port 8080
Qwen 전용으로 챙겨야 할 핵심 옵션은 다음 네 가지입니다:
--tool-call-parser qwen3_coder: Qwen3-Coder 계열의 tool call 출력 형식을 파싱--reasoning-parser qwen3: Qwen3의<think>...</think>추론 블록을 분리해서 별도 필드로 내려줌--enable-auto-tool-choice: 모델이 도구 호출 여부를 스스로 결정하도록 허용--quantization compressed-tensors: AWQ 4bit 모델을 로드하기 위한 양자화 형식 지정
--served-model-name qwen3p5는 클라이언트(Qwen-Code)에서 참조할 모델 이름이 됩니다. 아래에서 다룰 settings.json에서 이 이름을 그대로 사용합니다.
2. 인터넷망에서 패키지 준비
인터넷이 되는 PC에서 qwen-code를 의존성과 함께 다운로드합니다. 폴더 경로는 어디든 상관없습니다. 여기서는 다운로드 폴더에 만들어 봅시다:
1
2
3
4
mkdir C:\Users\{사용자이름}\Downloads\qwen-code-offline
cd C:\Users\{사용자이름}\Downloads\qwen-code-offline
npm init -y
npm install @qwen-code/qwen-code@latest
npm init -y는 현재 폴더에 빈 package.json만 만들어 둘 뿐 네트워크는 타지 않습니다. 실제 다운로드는 그다음 npm install 줄에서 일어나는데, -g 없이 로컬 설치하면 npm이 @qwen-code/qwen-code와 그 의존성 트리 전체를 현재 폴더의 node_modules 아래에 풀어 놓습니다. 의존성을 따로 받을 필요 없이 이 한 줄이면 충분합니다.
다운로드가 끝나면 qwen-code-offline 폴더 전체(node_modules 포함)를 압축해서 망간 자료 전송 시스템으로 폐쇄망에 옮깁니다.
3. 업무망에서 설치
이제 폐쇄망 PC로 옮긴 압축 파일을 풀고 설치를 진행해 봅시다. 폴더 위치는 어디든 상관없지만, 편의상 사용자\Projects 폴더를 만든 뒤에 그 아래로 풀겠습니다. 압축을 풀면 폴더 구조는 다음과 같습니다:
1
2
3
4
5
6
7
8
9
C:\Users\{사용자이름}\Projects\qwen-code-offline\
├─ package.json
├─ package-lock.json
└─ node_modules\
├─ .bin\
├─ @qwen-code\
│ └─ qwen-code\ ← 실제 qwen-code 패키지
├─ @lydell\
└─ @teddyzhu\
node_modules\@qwen-code\qwen-code\ 폴더로 들어가 보면 cli.js가 있습니다. 여기서 node cli.js를 실행해 봅시다:
1
2
cd C:\Users\{사용자이름}\Projects\qwen-code-offline\node_modules\@qwen-code\qwen-code
node .\cli.js
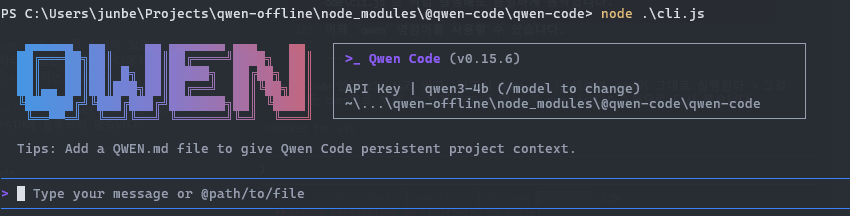
node cli.js로 띄운 Qwen Code CLI 첫 화면
이 그림이 나오면 실행은 잘된 겁니다. 즉 qwen 명령이 하는 일은 결국 이 cli.js를 실행하는 것뿐입니다. 우리가 하려는 일은 어느 폴더에서든 그냥 qwen이라고만 치면 이 cli.js가 실행되도록 PATH에 얹어 두는 것입니다. 같은 폴더에서 npm link를 한 번 실행하면 끝납니다:
1
npm link
이제 어느 폴더에서든 qwen 한 단어로 같은 화면을 띄울 수 있습니다.
4. 설정 파일 수정
아마 지금쯤 Qwen-Code를 한 번 띄워 봤다면 Windows 기준 C:\Users\{사용자이름}\.qwen\, Linux 기준 ~/.qwen/ 폴더가 자동으로 생성되어 있을 겁니다. 그 안에 settings.json 파일이 들어 있는데, 이걸 vLLM 서버에 맞게 수정해 봅시다:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
"security": {
"auth": {
"selectedType": "openai",
"apiKey": "EMPTY",
"baseUrl": "http://172.31.128.161:8080/v1"
}
},
"ui": {
"theme": "Qwen Light"
},
"$version": 3,
"model": {
"name": "qwen3p5",
"generationConfig": {
"contextWindowSize": 32768,
"samplingParams": {
"temperature": 0.6,
"top_p": 0.95,
"presence_penalty": 0.0,
"max_tokens": 8192
},
"extra_body": {
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
}
}
}
}
security.auth.apiKey: vLLM은 인증이 필요 없으므로"EMPTY"같은 임의 값이면 됩니다security.auth.baseUrl: vLLM 서버 주소 (포트까지 포함). 위 예시의http://172.31.128.161:8080/v1은 사내 vLLM 서버 IP이니 실제 환경에 맞춰 바꾸세요model.name: vLLM에서--served-model-name으로 지정한 모델 이름과 일치해야 합니다 (위docker-compose.yml에서qwen3p5로 지정함)model.generationConfig의temperature,top_p,top_k,min_p,presence_penalty,repetition_penalty값은 Qwen3.5-9B 모델 카드에서 권장하는 추천 샘플링 파라미터를 그대로 옮긴 것입니다. 모델이 바뀌면 해당 모델의 카드에서 권장 값을 확인해 맞추는 게 좋습니다.
5. 실행 확인
아무 디렉토리에서나 qwen을 실행할 수 있지만, 여기서는 ~/.qwen 폴더로 이동해서 qwen을 실행해 방금 수정한 설정 파일을 직접 읽고 설명하게 해 봅시다. PowerShell 7 기준입니다:
1
PS C:\Users\{사용자이름}\.qwen> qwen
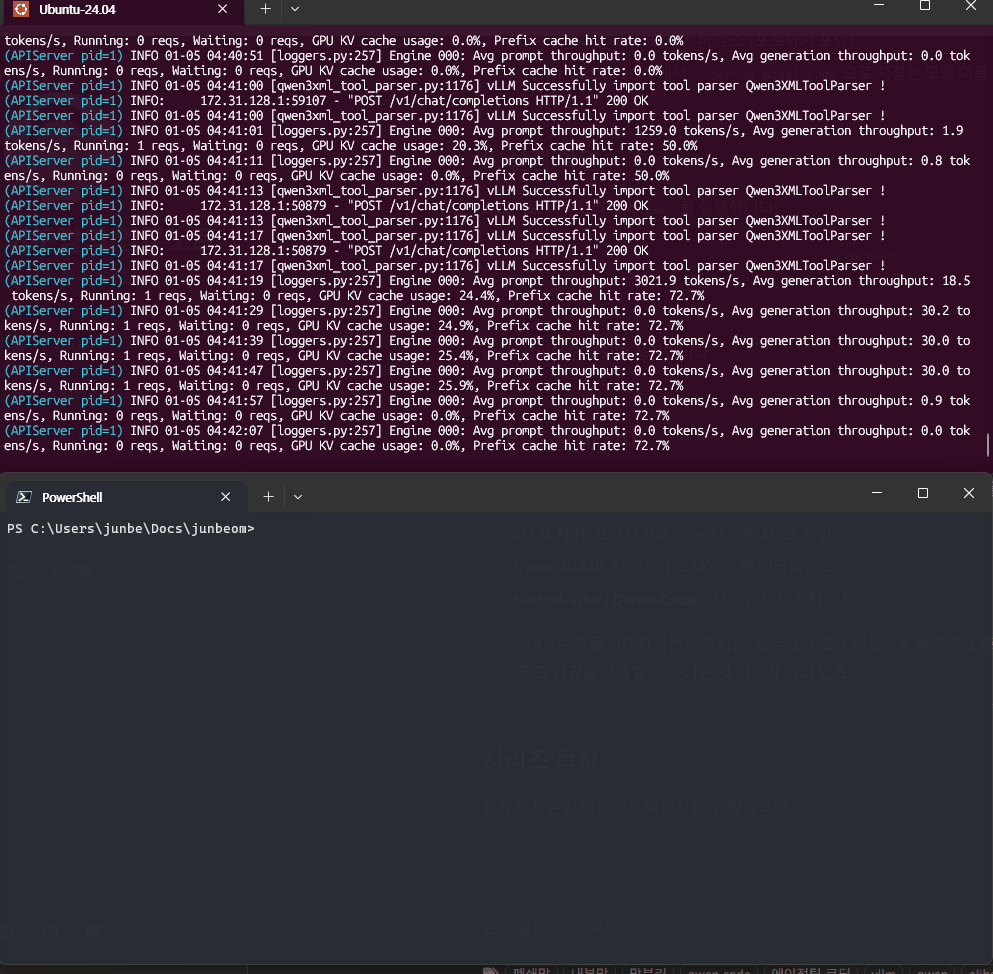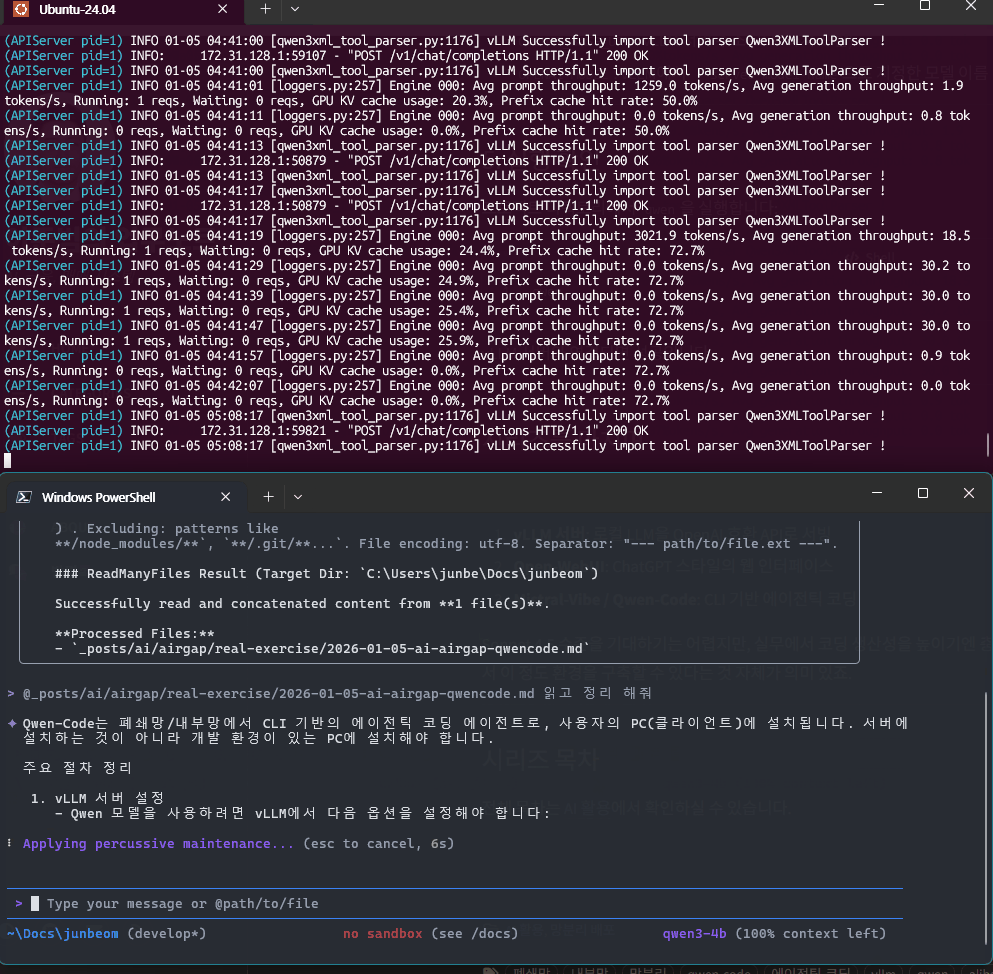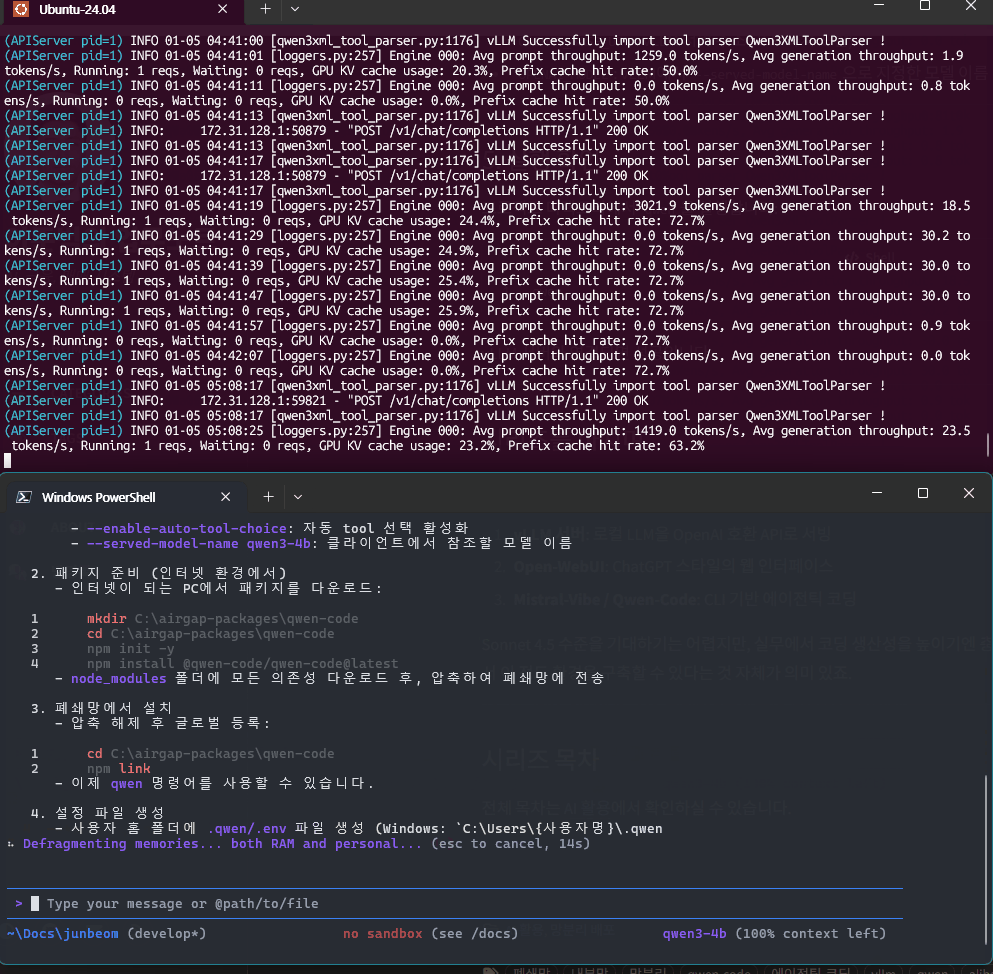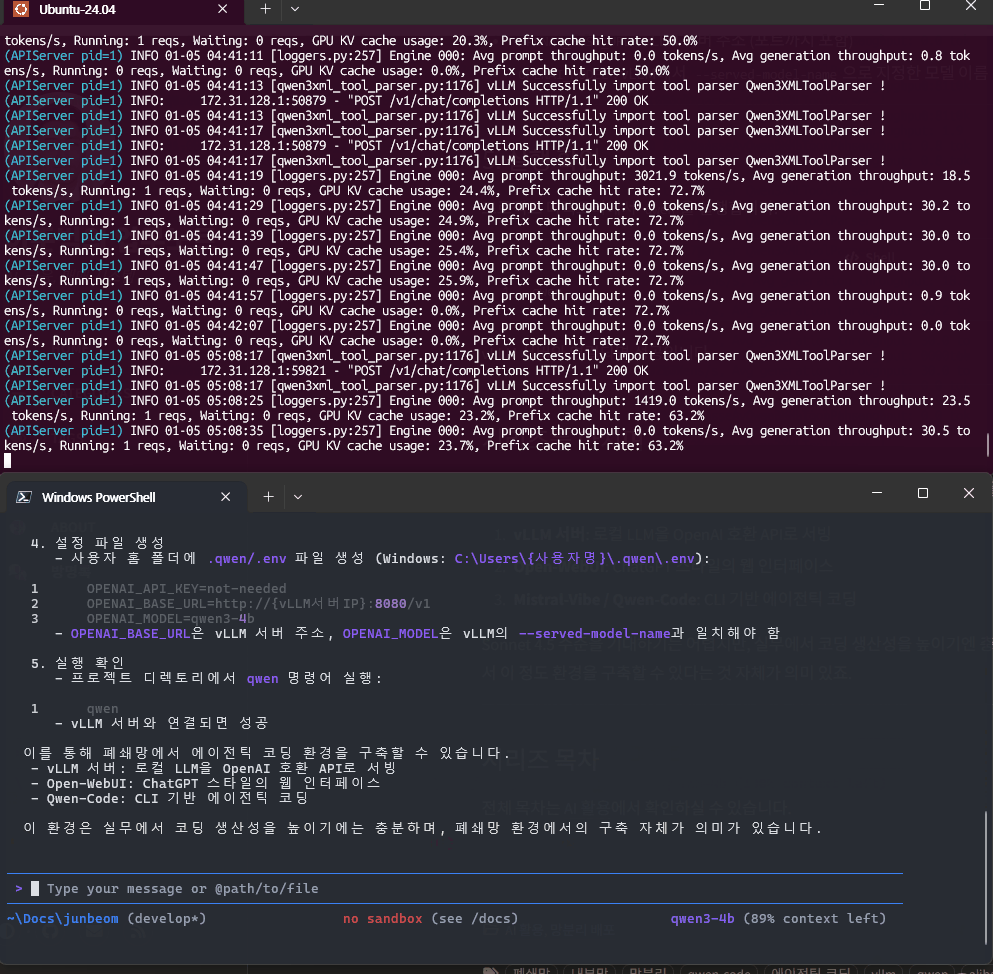 화면 위쪽은 vLLM 로그 창으로 Prefill/Decode 속도가 표시됩니다.
화면 위쪽은 vLLM 로그 창으로 Prefill/Decode 속도가 표시됩니다.
GIF 아래쪽 vLLM 로그를 보면 decode 속도는 30 tps 정도 나옵니다. vLLM 서버와 연결되면 성공입니다.
시리즈를 마치며
첫 번째 글에서 설정한 목표를 달성했습니다.
서버
- Docker 설치
- vLLM 이미지 설치
- Open-WebUI 이미지 설치
- LLM 모델 다운로드
- 임베딩 모델 다운로드
- vLLM으로 LLM 모델 서빙
- Open-WebUI를 임베딩 모델과 함께 구동
클라이언트
- 웹 채팅: Open-WebUI에 접속하면 끝
- 에이전틱 코딩: 모델에 따라 선택
- Mistral 계열 → Mistral-Vibe
- Qwen 계열 → Qwen-Code
- 기타 → Claude Code + claude-code-router
시리즈 목차
전체 목차는 AI 활용에서 확인하실 수 있습니다.