(OMS 5) 오더북 자료구조 구현 - 호가 데이터로 가격 레벨 관리
오더북 자료구조 구현 가이드 - Rust 기반 BTreeMap과 HashMap 조합으로 가격 레벨을 관리하고, 매칭 엔진에 필요한 O(1) 주문 조회와 O(log N) 가격 탐색을 모두 확보하는 방법을 다룹니다.
이전 글: 오더북이 필요한 이유
이 글은 매매 시스템 시리즈의 글입니다.
시리즈 전체 보기: OMS 시리즈
오더북은 매수 Ladder와 매도 Ladder를 합친 자료구조입니다. 효율적인 구현은 BTreeMap으로 가격을 정렬해 best price를 O(log N)에 찾고, AHashMap으로 주문 ID를 O(1)에 조회하며, 한 가격에 쌓인 주문은 VecDeque로 FIFO 처리하는 3계층 조합으로 만듭니다. 이 글은 그 자료구조 선택의 근거를 Rust 코드로 정리합니다.
이전 글에서 오더북이 왜 필요한지 살펴봤습니다. 이번 글에서는 효율적으로 동작하는 오더북을 작성해 보겠습니다. 실무에서는 사용자에 따라 훨씬 더 많은 요소가 추가되지만, 이 글에서는 핵심적인 부분만 다루겠습니다.
용어 정리
먼저 이 글에서 사용하는 용어를 정리하겠습니다.
- Level: 한 가격에 걸린 주문들의 나열
- Ladder: 한 방향(매수 또는 매도)의 Level들을 모은 것
- Orderbook: 매수 Ladder와 매도 Ladder를 합친 것
자료구조 선택
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
use ahash::AHashMap;
use std::collections::{BTreeMap, VecDeque};
type OrderId = u64;
type BookPrice = i64;
type BookQuantity = i64;
/// 한 가격의 주문 큐
struct Level {
price: BookPrice,
orders: VecDeque<(OrderId, BookQuantity)>,
total_quantity: BookQuantity,
}
/// 한 방향(매수 또는 매도)의 가격 레벨들
struct Ladder {
levels: BTreeMap<BookPrice, Level>,
cache: AHashMap<OrderId, BookPrice>,
}
/// 매수 + 매도
struct Orderbook {
bids: Ladder,
asks: Ladder,
}
왜 이런 자료구조를 선택했는지 하나씩 살펴보겠습니다.
AHashMap
cache에 사용한 AHashMap은 Rust 표준 라이브러리의 HashMap보다 빠른 해시맵입니다. 표준 HashMap은 HashDoS 공격 방어를 위해 SipHash를 사용하는데, 이 해싱 자체가 느립니다. AHashMap은 비암호학적 해시 함수를 사용해서 해시 연산이 대략 2~5배 빠릅니다.
Rust의 표준 라이브러리는 의도적으로 최소한의 기능만 포함합니다. 비동기 런타임도, JSON 파서도, HTTP 클라이언트도 없습니다. HashMap 역시 안전성에 중점을 둔 범용 구현이라, 성능이 중요한 상황에서는 더 나은 대체제가 있는지 항상 확인해 봐야 합니다.
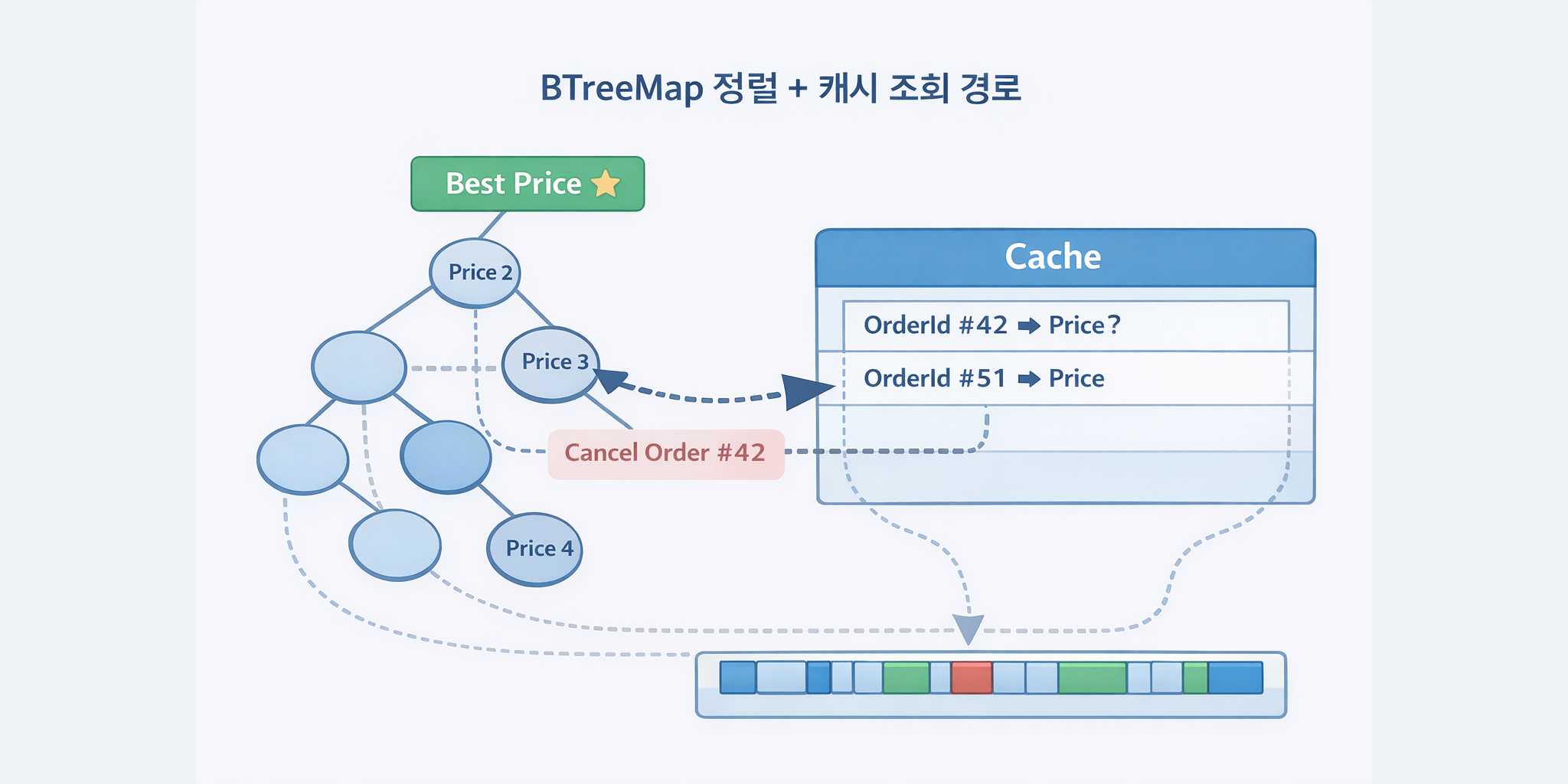
cache: 주문 ID → 가격
1
cache: AHashMap<OrderId, BookPrice>
이 변수가 없으면 주문 ID로 주문을 찾을 때 모든 가격 레벨을 순회해야 합니다. 주문 취소나 수정 요청이 들어오면 해당 주문이 어느 가격에 있는지 바로 알아야 하는데, 가격 레벨을 전부 순회하면 느립니다. cache가 있으면 O(1)에 가격을 찾고, 그 가격의 Level에서 바로 처리할 수 있습니다.
Ladder: BTreeMap
1
levels: BTreeMap<BookPrice, Level>
가격 레벨은 정렬되어 있어야 합니다. best price 갱신이 빈번하게 일어나고, 대량 주문이 여러 가격을 뜯어갈 때 최우선 호가부터 차례대로 체결됩니다. 정렬되어 있지 않으면 매번 best price를 찾기 위해 전체를 탐색해야 하고, 이 비용이 누적되면 성능상 큰 손실이 발생합니다.
BTreeMap은 키를 정렬된 상태로 유지하므로, 최솟값이나 최댓값을 O(log n)에 가져올 수 있습니다.
Level: VecDeque
1
orders: VecDeque<(OrderId, BookQuantity)>
주문의 체결은 앞에서 일어나고, 주문의 추가는 뒤에서 일어납니다. 전형적인 FIFO 큐이므로 양방향 큐인 VecDeque가 자연스럽습니다.
그런데 취소는 어떨까요? 통계적으로 취소의 80~90%는 큐 뒤쪽에서 발생하지만, 정확한 위치를 알기는 어렵습니다. 저는 비율 하나를 고정해서 사용합니다. 앞쪽과 뒤쪽을 대략 1:3 정도의 비율로 설정하고 탐색합니다.
자주 묻는 질문
왜 HashMap이 아닌 BTreeMap을 가격 레벨에 쓰나요?
매수 호가는 best price가 가장 높은 값, 매도 호가는 가장 낮은 값입니다. 대량 주문이 여러 가격을 뜯어갈 때 best price부터 차례로 체결되어야 하므로 정렬이 필수입니다. HashMap은 매번 전체를 훑어야 하지만 BTreeMap은 최솟값/최댓값을 O(log N)에 가져옵니다.
주문 취소는 어떻게 빠르게 처리하나요?
주문 ID로 가격을 모르면 모든 Level을 순회해야 합니다. cache: AHashMap<OrderId, BookPrice>를 두면 O(1)로 가격을 알아낸 뒤 해당 Level의 VecDeque만 탐색하면 됩니다. 통계적으로 취소의 80~90%가 큐 뒤쪽에서 발생하므로 앞:뒤 1:3 비율로 양방향 탐색합니다.
왜 표준 HashMap 대신 AHashMap인가요?
표준 HashMap은 HashDoS 방어용 SipHash를 써서 해시 자체가 느립니다. 비암호학적 해시인 AHashMap이 2~5배 빠르고, 매매 시스템처럼 신뢰된 입력만 들어오는 환경에서는 안전성 손실 없이 성능을 챙길 수 있습니다.
관련 글
- 오더북이 필요한 이유: 오더북의 용도
- 중요한 숫자 관리는 정수로: 가격을 정수로 관리하는 이유
- 메모리 얼라인먼트: 오더북 구조체의 메모리 배치 최적화
- 비트 패킹으로 주문 ID 최적화: OrderId 타입의 설계
- OMS 시리즈 인트로: 시리즈 전체 목차